import cv2, os, time
from models import models
from models2 import models2
# 不然每次YOLO处理都会输出调试信息
os.environ['YOLO_VERBOSE'] = 'False'
from ultralytics import YOLO
from PySide6.QtWidgets import QApplication, QMessageBox
from PySide6.QtUiTools import QUiLoader
from PySide6 import QtWidgets, QtCore, QtGui
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.lib.styles import getSampleStyleSheet,ParagraphStyle
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image,Table,TableStyle
from reportlab.lib.enums import TA_CENTER,TA_LEFT,TA_JUSTIFY
from reportlab.lib import colors
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import inch
# from tkinter import *
from tkinter.filedialog import asksaveasfile
from tkinter.filedialog import asksaveasfilename
class zhong:
def __init__(self):
self.setupUI()
# 定义定时器,用于控制显示视频的帧率
self.timer_camera = QtCore.QTimer()
# 定时到了,回调 self.show_camera
self.timer_camera.timeout.connect(self.show_camera)
# 加载 YOLO nano 模型,第一次比较耗时,要20秒左右
# self.model = YOLO('yolov8x-pose-p6.pt')
self.model = YOLO('yolov8n-pose.pt')
self.args()
def args(self):
self.list1 = []
self.list2 = []
self.list3 = []
self.list4 = []
self.time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
self.x1 = []
self.y1 = []
self.x2 = []
self.y2 = []
self.x3 = []
self.y3 = []
self.x4 = []
self.y4 = []
def setupUI(self):
# self.ui = QUiLoader().load('untitled.ui')
self.ui = QUiLoader().load('new.ui')
self.ui.displayButton.clicked.connect(self.displayPage1)
self.ui.displayButton_2.clicked.connect(self.displayPage2)
self.ui.displayButton_3.clicked.connect(self.displayPage3)
self.ui.displayButton_4.clicked.connect(self.displayPage4)
self.ui.displayButton_5.clicked.connect(self.displayPage5)
self.ui.camBtn.clicked.connect(self.startCamera)
self.ui.stopBtn.clicked.connect(self.stop)
self.ui.pdfsubmit.clicked.connect(self.pdf)
# 拍照
# self.ui.takeBtn.clicked.connect(self.taking_pictures)
self.ui.takeBtn1.clicked.connect(self.taking_pictures1)
self.ui.takeBtn2.clicked.connect(self.taking_pictures2)
self.ui.takeBtn3.clicked.connect(self.taking_pictures3)
self.ui.takeBtn4.clicked.connect(self.taking_pictures4)
#修改
self.ui.fixBtn1.clicked.connect(self.fix1)
self.ui.fixBtn2.clicked.connect(self.fix2)
self.ui.fixBtn3.clicked.connect(self.fix3)
self.ui.fixBtn4.clicked.connect(self.fix4)
#显示实时时间
self.ui.time.setText(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
def startCamera(self):
self.cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
if not self.cap.isOpened():
print("1号摄像头不能打开")
return ()
if self.timer_camera.isActive() == False: # 若定时器未启动
# self.timer_camera.start(50)
#100帧
self.timer_camera.start(30)
# self.timer_camera.start(20)
def show_camera(self):
ret, frame = self.cap.read() # 从视频流中读取
if not ret:
return
# 把读到的16:10帧的大小重新设置
frame = cv2.resize(frame, (800, 600))
# 视频色彩转换回RGB,OpenCV images as BGR
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# qImage = QtGui.QImage(frame.data, frame.shape[1], frame.shape[0],
# QtGui.QImage.Format_RGB888) # 变成QImage形式
# 往显示视频的Label里 显示QImage
# self.ui.label_ori_video.setPixmap(QtGui.QPixmap.fromImage(qImage))
results = self.model(frame)[0]
# print(results)
img = results.plot(line_width=1)
qImage = QtGui.QImage(img.data, img.shape[1], img.shape[0],
QtGui.QImage.Format_RGB888) # 变成QImage形式
self.ui.label_treated.setPixmap(QtGui.QPixmap.fromImage(qImage)) # 往显示Label里 显示QImage
self.ui.label_treated_2.setPixmap(QtGui.QPixmap.fromImage(qImage)) # 往显示Label里 显示QImage
self.ui.label_treated_3.setPixmap(QtGui.QPixmap.fromImage(qImage)) # 往显示Label里 显示QImage
self.ui.label_treated_4.setPixmap(QtGui.QPixmap.fromImage(qImage)) # 往显示Label里 显示QImage
def taking_pictures1(self):
ret, frame = self.cap.read() # 从视频流中读取
if not ret:
return
# 把读到的16:10帧的大小重新设置
frame = cv2.resize(frame, (800, 600))
# 视频色彩转换回RGB,OpenCV images as BGR
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
qImage = QtGui.QImage(frame.data, frame.shape[1], frame.shape[0],
QtGui.QImage.Format_RGB888) # 变成QImage形式
# 往显示视频的Label里 显示QImage
# self.ui.label_take1.setPixmap(QtGui.QPixmap.fromImage(qImage))
qImage.save('pose1.jpg')
self.list1.clear()
angel_shoulder, str_shoulder, angel_xo1, angel_xo2, str_xo, diff_leg, str2_leg ,x,y= models('pose1.jpg').sum()
self.list1.append(angel_shoulder)
self.list1.append(str_shoulder)
self.list1.append( angel_xo1)
self.list1.append(angel_xo2)
self.list1.append( str_xo)
self.list1.append( diff_leg)
self.list1.append( str2_leg)
self.x1 = x
self.y1 = y
#展示qimage
# self.ui.label_show1.setPixmap(QtGui.QPixmap.fromImage(qImage))
#打开本地图片并展示
pixmap = QtGui.QPixmap('pose1.jpg_keypoint.jpg')
self.ui.label_show1.setPixmap(pixmap)
def taking_pictures2(self):
ret, frame = self.cap.read() # 从视频流中读取
if not ret:
return
# 把读到的16:10帧的大小重新设置
frame = cv2.resize(frame, (800, 600))
# 视频色彩转换回RGB,OpenCV images as BGR
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
qImage = QtGui.QImage(frame.data, frame.shape[1], frame.shape[0],
QtGui.QImage.Format_RGB888) # 变成QImage形式
# 往显示视频的Label里 显示QImage
# self.ui.label_take2.setPixmap(QtGui.QPixmap.fromImage(qImage))
qImage.save('pose2.jpg')
self.list2.clear()
angel_head, str_head , x , y= models('pose2.jpg').head()
self.list2.append(angel_head)
self.list2.append(str_head)
self.x2 = x
self.y2 = y
# self.ui.label_show2.setPixmap(QtGui.QPixmap.fromImage(qImage))
pixmap = QtGui.QPixmap('pose2.jpg_keypoint.jpg')
self.ui.label_show2.setPixmap(pixmap)
def taking_pictures3(self):
ret, frame = self.cap.read() # 从视频流中读取
if not ret:
return
# 把读到的16:10帧的大小重新设置
frame = cv2.resize(frame, (800, 600))
# 视频色彩转换回RGB,OpenCV images as BGR
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
qImage = QtGui.QImage(frame.data, frame.shape[1], frame.shape[0],
QtGui.QImage.Format_RGB888) # 变成QImage形式
# 往显示视频的Label里 显示QImage
# self.ui.label_take3.setPixmap(QtGui.QPixmap.fromImage(qImage))
qImage.save('pose3.jpg')
self.list3.clear()
angel_pelvis,str_pelvis ,x,y= models('pose3.jpg').Pelvis()
self.list3.append(angel_pelvis)
self.list3.append(str_pelvis)
self.x3 = x
self.y3 = y
# self.ui.label_show3.setPixmap(QtGui.QPixmap.fromImage(qImage))
pixmap = QtGui.QPixmap('pose3.jpg_keypoint.jpg')
self.ui.label_show3.setPixmap(pixmap)
def taking_pictures4(self):
ret, frame = self.cap.read() # 从视频流中读取
if not ret:
return
# 把读到的16:10帧的大小重新设置
frame = cv2.resize(frame, (800, 600))
# 视频色彩转换回RGB,OpenCV images as BGR
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
qImage = QtGui.QImage(frame.data, frame.shape[1], frame.shape[0],
QtGui.QImage.Format_RGB888) # 变成QImage形式
# 往显示视频的Label里 显示QImage
# self.ui.label_take4.setPixmap(QtGui.QPixmap.fromImage(qImage))
qImage.save('pose4.jpg')
self.list4.clear()
angel_shoulder, str_shoulder, angel_xo1, angel_xo2, str_xo, diff_leg, str2_leg,x,y = models('pose4.jpg').sum()
self.list4.append(angel_shoulder)
self.list4.append(str_shoulder)
self.list4.append(angel_xo1)
self.list4.append(angel_xo2)
self.list4.append(str_xo)
self.list4.append(diff_leg)
self.list4.append(str2_leg)
self.x4 = x
self.y4 = y
# self.ui.label_show4.setPixmap(QtGui.QPixmap.fromImage(qImage))
pixmap = QtGui.QPixmap('pose4.jpg_keypoint.jpg')
self.ui.label_show4.setPixmap(pixmap)
def stop(self):
self.timer_camera.stop() # 关闭定时器
self.cap.release() # 释放视频流
self.ui.label_treated.clear() # 清空视频显示区域
self.ui.label_treated_2.clear() # 清空视频显示区域
self.ui.label_treated_3.clear() # 清空视频显示区域
self.ui.label_treated_4.clear() # 清空视频显示区域
def pdf(self):
id = self.ui.id.toPlainText()
name = self.ui.name.toPlainText()
age = self.ui.age.toPlainText()
sex = self.ui.sex.currentText()
time = self.time
if(self.list1 == [] or self.list2 == [] or self.list3 == [] or self.list4 == []):
msg_box = QMessageBox(QMessageBox.Warning, '警告', '请确保所有视图都已采集')
msg_box.exec_()
else:
self.pdf_process(id,name, age, sex,time, self.list1, self.list2, self.list3, self.list4)
def displayPage1(self):
self.ui.stackedWidget.setCurrentIndex(0)
def displayPage2(self):
self.ui.stackedWidget.setCurrentIndex(1)
def displayPage3(self):
self.ui.stackedWidget.setCurrentIndex(2)
def displayPage4(self):
self.ui.stackedWidget.setCurrentIndex(3)
def displayPage5(self):
self.ui.stackedWidget.setCurrentIndex(4)
def mouse(self, imgs,x_center,y_center,radius):
def mouse_LButtonDown(event, x, y, flags, param):
global temp
if event == cv2.EVENT_LBUTTONDOWN:
for i in range(len(x_center)):
if (x - x_center[i]) ** 2 + (y - y_center[i]) ** 2 <= radius ** 2:
temp = i
if event == cv2.EVENT_LBUTTONUP:
x_center[temp] = x
y_center[temp] = y
cv2.namedWindow('Modify', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Modify', 800, 600)
cv2.setMouseCallback('Modify', mouse_LButtonDown)
color = (0, 255, 0)
while True:
img = cv2.imread(imgs)
for i in range(len(x_center)):
cv2.circle(img, (x_center[i], y_center[i]), 4, color, -1, lineType=cv2.FILLED)
cv2.imshow('Modify', img)
key = cv2.waitKey(1)
if key == ord('q'):
break
cv2.destroyAllWindows()
return x_center, y_center
def fix1(self):
x_center,y_center = self.mouse("pose1.jpg",self.x1,self.y1,10)
angel_shoulder, str_shoulder, angel_xo1, angel_xo2, str_xo, diff_leg, str2_leg = models2("pose1.jpg", x_center,
y_center).sum()
pixmap = QtGui.QPixmap('pose1.jpg')
self.ui.label_show1.setPixmap(pixmap)
self.list1.clear()
self.list1.append(angel_shoulder)
self.list1.append(str_shoulder)
self.list1.append(angel_xo1)
self.list1.append(angel_xo2)
self.list1.append(str_xo)
self.list1.append(diff_leg)
self.list1.append(str2_leg)
def fix2(self):
x_center,y_center = self.mouse("pose2.jpg", self.x2, self.y2, 10)
angel_head, str_head = models2("pose2.jpg", x_center,y_center).head()
pixmap = QtGui.QPixmap('pose2.jpg')
self.ui.label_show2.setPixmap(pixmap)
self.list2.clear()
self.list2.append(angel_head)
self.list2.append(str_head)
def fix3(self):
x_center,y_center = self.mouse("pose3.jpg", self.x3, self.y3, 10)
angel_pelvis, str_pelvis = models2("pose3.jpg", x_center,y_center).Pelvis()
pixmap = QtGui.QPixmap('pose3.jpg')
self.ui.label_show3.setPixmap(pixmap)
self.list3.clear()
self.list3.append(angel_pelvis)
self.list3.append(str_pelvis)
def fix4(self):
x_center,y_center = self.mouse("pose4.jpg", self.x4, self.y4, 10)
angel_shoulder, str_shoulder, angel_xo1, angel_xo2, str_xo, diff_leg, str2_leg = models2("pose4.jpg", x_center,y_center).sum()
pixmap = QtGui.QPixmap('pose4.jpg')
self.ui.label_show4.setPixmap(pixmap)
self.list4.clear()
self.list4.append(angel_shoulder)
self.list4.append(str_shoulder)
self.list4.append(angel_xo1)
self.list4.append(angel_xo2)
self.list4.append(str_xo)
self.list4.append(diff_leg)
self.list4.append(str2_leg)
def pdf_process(self,id,name,age,sex,time,list1,list2,list3,list4):
filetypes = [('PDF files', '*.pdf')]
# 获取用户想要保存的文件名和路径
file_path = asksaveasfilename(filetypes=filetypes, defaultextension='.pdf')
if not file_path:
return # 用户取消了操作
'''
生成pdf
'''
# 设置中文字体名称为微软雅黑
pdfmetrics.registerFont(TTFont('msyh', 'msyh.ttf'))
# 容纳所有的PDF元素
self.elements = []
'''
添加标题文字
'''
# 读取reportlab定义好的样式表
style = getSampleStyleSheet()
title = """ <para><font face="msyh">体态系统报告</font></para>"""
self.elements.append(Paragraph(title, style['Title']))
self.elements.append(Spacer(1, 0.2 * inch))
'''
添加小标题
'''
self.elements.append(Paragraph("""<font face="msyh">1. 用户信息</font>""", style["h3"]))
self.elements.append(Spacer(1, 0.2 * inch))
# 绘制表格
def draw_table(*args):
col_width = 100
style = [
('FONTNAME', (0, 0), (-1, -1), 'msyh'), # 字体
('BACKGROUND', (0, 0), (-1, 0), '#d5dae6'), # 设置第一行背景颜色
('ALIGN', (0, 0), (-1, -1), 'CENTER'), # 对齐
('VALIGN', (-1, 0), (-2, 0), 'MIDDLE'), # 对齐
('GRID', (0, 0), (-1, -1), 0.5, colors.grey), # 设置表格框线为grey色,线宽为0.5
]
table = Table(args, colWidths=col_width, style=style)
return table
# 添加表格数据
data = [('编号', '姓名', '年龄', '性别', '时间'),
(id, name, age, sex, time)
]
self.elements.append(draw_table(*data))
angel_shoulder = list1[0]
str_shoulder = list1[1]
angel_xo1 = list1[2]
angel_xo2 = list1[3]
str_xo = list1[4]
diff_leg = list1[5]
str2_leg = list1[6]
self.elements.append(Paragraph("""<font face="msyh">2. 体检结果</font>""", style["h3"]))
self.elements.append(Spacer(1, 0.2 * inch))
content2 = " ① 肩膀度数: " + str(angel_shoulder) + "°,肩膀状态: " + str_shoulder + ";"
description2 = """
<para>
<font face="msyh">
""" + content2 + """
</font>
</para>
"""
self.elements.append(Paragraph(description2, style["h5"]))
self.elements.append(Spacer(1, 0.2 * inch))
'''
分开
'''
content2 = " ②长短腿状态: " + str2_leg + " ;"
description2 = """
<para>
<font face="msyh">
""" + content2 + """
</font>
</para>
"""
self.elements.append(Paragraph(description2, style["h5"]))
self.elements.append(Spacer(1, 0.2 * inch))
content2 = " ③腿型度数: 右腿" + str(angel_xo1) + "°,左腿: " + str(
angel_xo2) + "°,腿型判断: " + str_xo + ";"
description2 = """
<para>
<font face="msyh">
""" + content2 + """
</font>
</para>
"""
self.elements.append(Paragraph(description2, style["h5"]))
self.elements.append(Spacer(1, 0.2 * inch))
'''
以下均为测试内容
'''
angel_head = list2[0]
str_head = list2[1]
content2 = " ④ 头部前倾度数: " + str(
angel_head) + "°,头部状态: " + str_head + ";"
description2 = """
<para>
<font face="msyh">
""" + content2 + """
</font>
</para>
"""
self.elements.append(Paragraph(description2, style["h5"]))
self.elements.append(Spacer(1, 0.2 * inch))
angel_pelvis = list3[0]
str_pelvis = list3[1]
content2 = " ⑤ 盆骨前倾度数: " + str(
angel_pelvis) + "°,盆骨状态: " + str_pelvis + ";"
description2 = """
<para>
<font face="msyh">
""" + content2 + """
</font>
</para>
"""
self.elements.append(Paragraph(description2, style["h5"]))
self.elements.append(Spacer(1, 0.2 * inch))
'''
此处截止
'''
'''
添加小标题
'''
from reportlab.platypus import Image
self.elements.append(Paragraph("""<font face="msyh">3. 模型检测的四视图</font>""", style["h3"]))
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">3.1 正视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img1 = cv2.imread('pose1.jpg_keypoint.jpg')
resize1 = cv2.resize(img1, (350, 300))
cv2.imwrite('pose1.jpg_keypoint.jpg', resize1)
img1 = Image('pose1.jpg_keypoint.jpg')
self.elements.append(img1)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">3.2 左视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img2 = cv2.imread('pose2.jpg_keypoint.jpg')
resize2 = cv2.resize(img2, (350, 300))
cv2.imwrite('pose2.jpg_keypoint.jpg', resize2)
img2 = Image('pose2.jpg_keypoint.jpg')
self.elements.append(img2)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">3.3 后视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img3 = cv2.imread('pose3.jpg_keypoint.jpg')
resize3 = cv2.resize(img3, (350, 300))
cv2.imwrite('pose3.jpg_keypoint.jpg', resize3)
img3 = Image('pose3.jpg_keypoint.jpg')
self.elements.append(img3)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">3.4 俯视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img4 = cv2.imread('pose4.jpg_keypoint.jpg')
resize4 = cv2.resize(img4, (350, 300))
cv2.imwrite('pose4.jpg_keypoint.jpg', resize4)
img4 = Image('pose4.jpg_keypoint.jpg')
self.elements.append(img4)
# 原始图片或者修改后的图片
self.elements.append(Paragraph("""<font face="msyh">4. 修改后的四视图</font>""", style["h3"]))
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">4.1 正视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img1 = cv2.imread('pose1.jpg')
resize1 = cv2.resize(img1, (350, 300))
cv2.imwrite('pose1.jpg', resize1)
img1 = Image('pose1.jpg')
self.elements.append(img1)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">4.2 左视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img2 = cv2.imread('pose2.jpg')
resize2 = cv2.resize(img2, (350, 300))
cv2.imwrite('pose2.jpg', resize2)
img2 = Image('pose2.jpg')
self.elements.append(img2)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">4.3 后视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img3 = cv2.imread('pose3.jpg')
resize3 = cv2.resize(img3, (350, 300))
cv2.imwrite('pose3.jpg', resize3)
img3 = Image('pose3.jpg')
self.elements.append(img3)
self.elements.append(Spacer(1, 0.2 * inch))
self.elements.append(Paragraph("""<font face="msyh">4.4 俯视图</font>""", style["h4"]))
self.elements.append(Spacer(1, 0.2 * inch))
img4 = cv2.imread('pose4.jpg')
resize4 = cv2.resize(img4, (350, 300))
cv2.imwrite('pose4.jpg', resize4)
img4 = Image('pose4.jpg')
self.elements.append(img4)
self.elements.append(Spacer(1, 0.2 * inch))
# 生成PDF文件
# name = str(name) + '_体态系统报告.pdf'
doc = SimpleDocTemplate(
file_path,
pagesize=(A4[0], A4[1]),
topMargin=30,
bottomMargin=30
)
doc.build(self.elements)
#写入pdf文件
import os
os.system(name)
# 将pdf另存其他路径
# os.rename(name, 'D:/Python/test/'+name)
# 删除中间文件
# os.remove('pose1.jpg')
# os.remove('pose2.jpg')
# os.remove('pose3.jpg')
# os.remove('pose4.jpg')
# os.remove('pose1.jpg_keypoint.jpg')
# os.remove('pose2.jpg_keypoint.jpg')
# os.remove('pose3.jpg_keypoint.jpg')
# os.remove('pose4.jpg_keypoint.jpg')
if __name__ == '__main__':
app = QApplication([])
zhongke = zhong()
zhongke.ui.show()
app.exec()
reportlab生成pdf,tkinter将pdf另存为其他路径
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/763882.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章
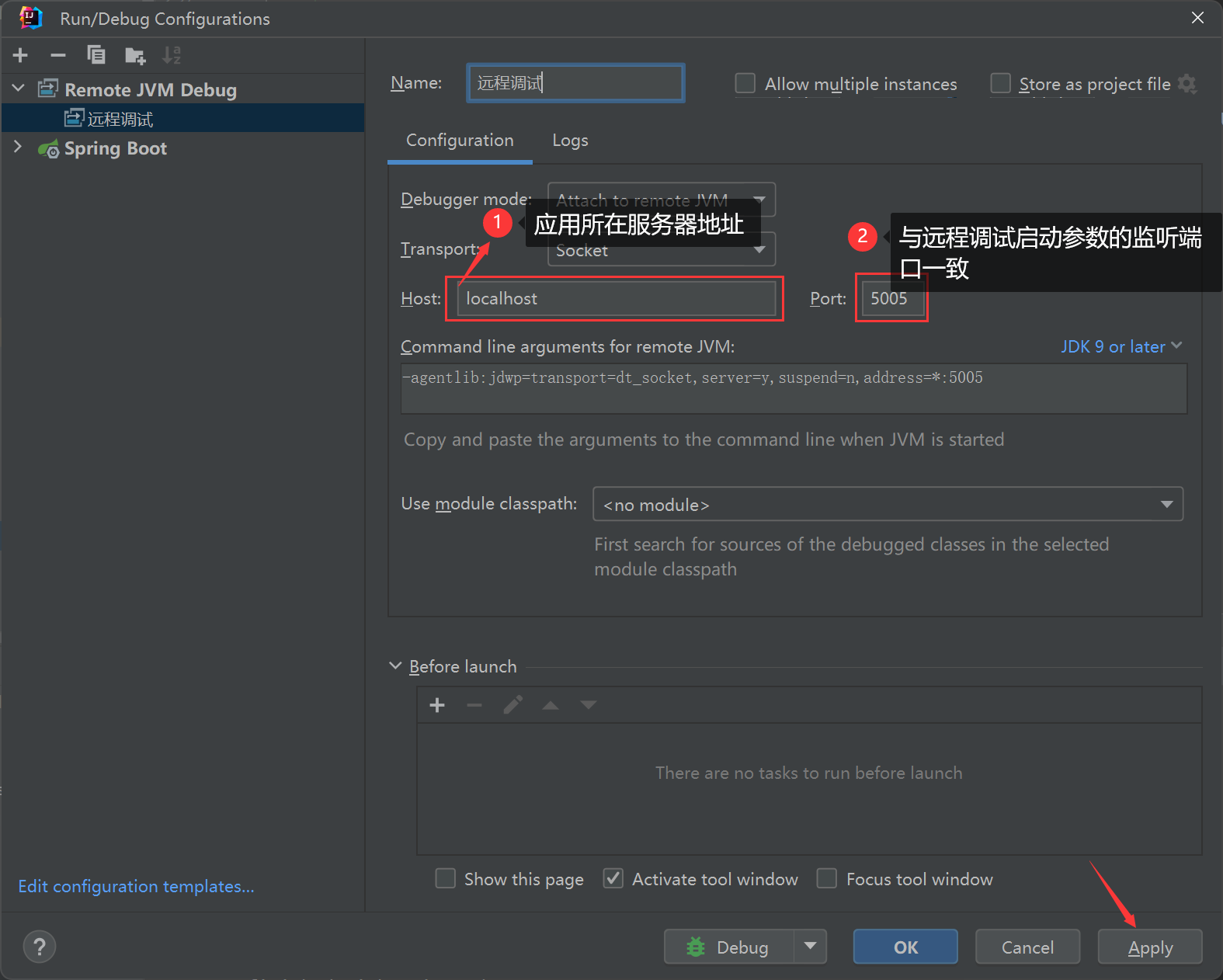
Java服务器代码远程调试(IDEA版)
Java服务器代码远程调试 配置启动脚本参数配置IDEA远程调试工具操作步骤 注意:远程调试的代码需要与本地代码一致,远程调试目的是解决本地环境无法支持调试的情况下,解决线上(测试)环境调试问题。 配置启动脚本参数
n…
昇思25天学习打卡营第10天|linchenfengxue
基于MobileNetv2的垃圾分类
通过读取本地图像数据作为输入,对图像中的垃圾物体进行检测,并且将检测结果图片保存到文件中。
MobileNetv2模型原理介绍
MobileNet网络是由Google团队于2017年提出的专注于移动端、嵌入式或IoT设备的轻量级CNN网络&#x…

TikTok直播限流与网络的关系及解决方法
TikTok作为一款热门的社交平台,其直播功能吸引了大量用户。然而,一些用户可能会遇到TikTok直播限流的问题,例如直播过程中出现播放量低、直播画面质量差等情况。那么,TikTok直播限流与所使用的网络线路是否有关系?是否…

TypeScript Project References npm 包构建小实践
npm 包输出 es/cjs 产物
在开发一个 npm 包时,通常需要同时输出 ES 模块和 CommonJS 模块的产物供不同的构建进行使用。在只使用tsc进行产物编译的情况下,我们通常可以通过配置两个独立的 tsconfig.json 配置文件,并在一个 npm script 中 执…
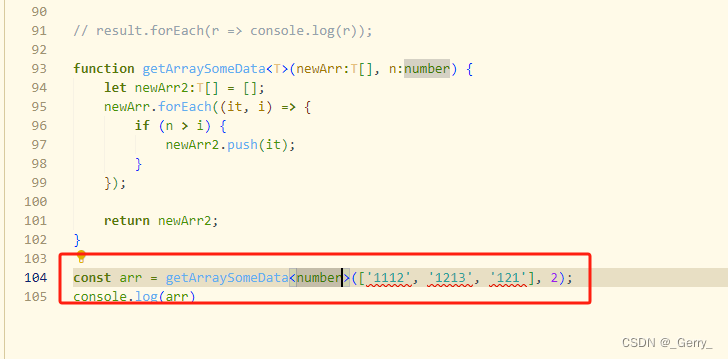
typescript学习回顾(五)
今天来分享一下ts的泛型,最后来做一个练习
泛型
有时候,我们在书写某些函数的时候,会丢失一些类型信息,比如我下面有一个例子,我想提取一个数组的某个索引之前的所有数据
function getArraySomeData(newArr, n:numb…
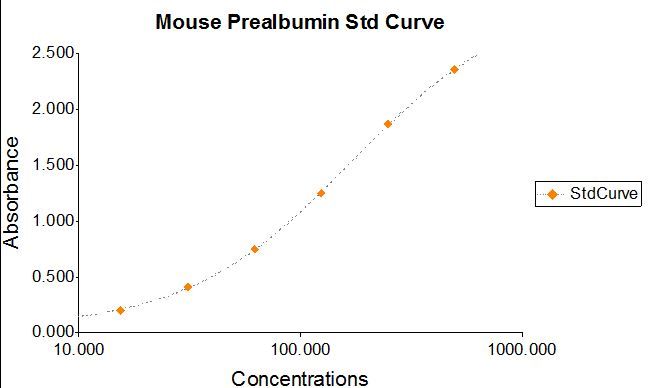
Mouse Prealbumin ELISA Kit小鼠前白蛋白ELISA试剂盒
前白蛋白(PRE)是一种由4条相同的多肽链组成的四聚体蛋白。电泳时,它比血清白蛋白的迁移速度更快,PRE可以作为多种疾病患者营养评价的标志物。ICL的Mouse Prealbumin ELISA Kit应用双抗体夹心法测定小鼠样本中前白蛋白水平…
CentOS7源码安装nginx并编写服务脚本
华子目录 准备下载nginx源码包关闭防火墙关闭selinux安装依赖环境 解压编译安装测试编写服务脚本,通过systemctl实现服务启动与关闭测试 准备
下载nginx源码包
在源码安装前,我们得先下载nginx源码包https://nginx.org/download/这里我下载的是nginx-1…
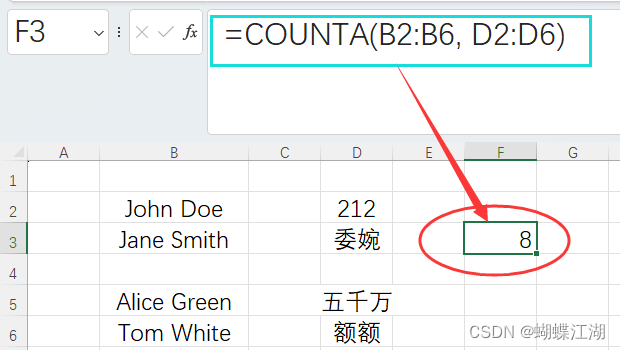
《梦醒蝶飞:释放Excel函数与公式的力量》8.2 COUNTA函数
8.2 COUNTA函数
COUNTA函数是Excel中用于统计指定区域内所有非空单元格数量的函数。它能够统计数值、文本、错误值以及公式返回的结果,是数据分析中常用的统计工具。
8.2.1 函数简介
COUNTA函数用于统计指定区域中所有非空单元格的数量。它与COUNT函数不同&#…

transformer——多变量预测PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)——transformer多变量预测
写在最前:
在系统地学习了Transformer结构后,尝试使用Transformer模型对DNA序列数据实现二分类,好久前就完成了这个实验,一直拖着没有整理,今天系统的记录一下,顺便记录一下自己踩过的坑
(需要…

OpenHarmony开发实战:GPIO控制器接口
功能简介
GPIO(General-purpose input/output)即通用型输入输出。通常,GPIO控制器通过分组的方式管理所有GPIO管脚,每组GPIO有一个或多个寄存器与之关联,通过读写寄存器完成对GPIO管脚的操作。
GPIO接口定义了操作GP…
Echarts 问题集锦
最近公司集中做统计图表,新手小白,真被Echarts折腾地不轻,怕自己年老记忆衰退,特地做一些记录。以备后面查阅。
1、X轴的 数据显示不全,间或不显示 很奇葩,我发现数据里有一个值为0.0,当这条记…

液压件工厂的MES解决方案:智能生产,高效未来
一、引言
虽然我国液压件行业发展迅速,但是大多数液压件生产企业规模小、自主创新能力不足,大部分液压产品处于价值链中低端。且由于技术、工艺、设备及管理等多方面的限制,高端液压件产品研发生产水平不足,无法形成有效的供给&a…
【linux】虚拟机安装 BCLinux-R8-U4-Server-x86_64
目录
一、概述
1.1移动云Linux系统订阅服务 CLS
1.2 大云天元操作系统BC-Linux
二、安装 一、概述 1.1移动云Linux系统订阅服务 CLS 移动云Linux系统订阅服务 CLS (Cloud Linux Service)为使用BC-Linux操作系统的用户提供标准维保服务以及高级技术支…
基于java+springboot+vue实现的社团管理系统(文末源码+Lw)270
摘 要
互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对信息管理混乱,出错率高,信息安全性差&#…
Linux4(Docker)
目录
一、Docker介绍
二、Docker结构
三、Docker安装 四、Docker 镜像
五、Docker 容器
六、Docker 安装nginx
七、Docker 中的MySQL部署 一、Docker介绍 Docker:是给予Go语言实现的开源项目。 Docker的主要目标是“Build,Ship and Run Any App,Anywhere” 也…

LangChain入门学习笔记(七)—— 使用检索提高生成内容质量
大模型训练使用的数据是开放的、广泛的,因此它显得更加的通用。然而在有些应用场景下,用户需要使用自己的数据使得大模型生成的内容更加贴切,也有时候用户的数据是敏感的,无法提供出来给大模型进行通用性的训练。RAG技术就是一种解…
HarmonyOS APP应用开发项目- MCA助手(Day02持续更新中~)
简言:
gitee地址:https://gitee.com/whltaoin_admin/money-controller-app.git端云一体化开发在线文档:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V5/agc-harmonyos-clouddev-view-0000001700053733-V5注:…
Java Lambda语法介绍
目录
一、概述
二、Lambda语法的历史
2.1 Lambda名字的含义
2.2 Lambda的历史
三、Lambda语法的核心接口
3.1 Lambda的四大核心接口
3.1.1 概述
3.1.2 Consumer 接口
3.1.3 Supplier 接口
3.1.4 Function 接口,>
3.1.5 Predicate 接口
四、Lambda的引用
4.1 概…

启航IT世界:高考后假期的科技探索之旅
随着高考的落幕,新世界的大门已经为你们敞开。这个假期,不仅是放松身心的时光,更是为即将到来的IT学习之旅打下坚实基础的黄金时期。以下是一份专为你们准备的IT专业入门预习指南,希望能助你们一臂之力。
一:筑基篇&a…
最新文章
- 那么大的一个车卖24.9万?一起来看24款大众途昂
- 浪漫午后夏日茶歇
- 申城下周晴雨参半,高考期间多阴雨天气
- 极氪007开卷了,007新增后驱增强版
- 【已解决】使用token登录机制,token获取不到,blog_list.html界面加载不出来
- MySQL8找不到my.ini配置文件以及报sql_mode=only_full_group_by解决方案
- vivado 物理优化约束、交互式物理优化
- Linux:Gitlab:16.9.2 创建用户及项目仓库基础操作(2)
- 5.1.4、【AI技术新纪元:Spring AI解码】Amazon Bedrock
- 【C++ 哈希】
- PyTorch学习笔记之基础函数篇(十三)
- 敏捷开发——elementUI/Vue使用/服务器部署
- VS Code中关于行操作的快捷键全解
- 最新发布!MySQL 9.0 的向量 (VECTOR) 类型文档更新
- 掌握Mojolicious会话管理:构建安全、持久的Web应用
- golang 模板引擎常用语法
- RPM包管理-rpm命令管理
- AI是在帮助开发者还是取代他们?
- 如何防止网络攻击?
- 做一个个人博客第一步该怎么做?零基础就找一个现成的模板学一学呗
- # 学习 Prolog 和 离散逻辑的16个等价公式:一趟有趣的逻辑之旅
- #tmux# #终端# 常用工具tmux
- #Ts篇:booleannumberstring[]元组枚举unknownvoidnull-undefined联合类型交叉类型等
- (1)(1.13) SiK无线电高级配置(五)